Classification of Personal Story Audio Data As True or False
Project Overview
This project aimed to develop a machine learning model to predict whether an audio story is true or false. This is a supervised binary classification problem.
The project explored and compared different machine learning models, feature extraction techniques, and validation strategies to develop a reliable system for detecting true or false audio stories.
Results
The ensemble model, despite achieving high accuracy during hyperparameter tuning, yielded disappointing results on the testing data, with an accuracy of only 48.19%. This indicates overfitting to the training data and a lack of generalisability to unseen data.
Logistic Regression achieved the highest testing accuracy among individual models (61.45%).
The poor performance can be attributed to:
Overfitting of models to the training data.
Potentially suboptimal feature selection.
Limitations in dataset size or diversity.
The subjective nature of truthfulness in storytelling.
Conclusions
Building accurate deception detection systems, particularly with subjective audio data, is challenging. The project highlighted the difficulties in identifying truly informative features and mitigating overfitting.
Dataset
The project utilises the MLEnd Deception Dataset. The dataset was split into training and testing sets (80/20) before feature extraction to prevent data leakage. Audio recordings were divided into non-overlapping 30-second segments.
To ensure the IID (Independent and Identically Distributed) assumption:
The data was split into training and testing sets with an 80/20 split.
Splitting was based on file paths to ensure segments from the same story weren't mixed between sets.
30-second non-overlapping segments ensured each segment was treated as an independent data point.
Methodology
Feature Engineering:
Several features were extracted from each audio segment, including acoustic features (pitch, voicing, energy, power, MFCCs) and phonetic features (shimmer)
Feature Scaling: Standard scaling was applied to the training and testing data separately.
Feature Reduction:
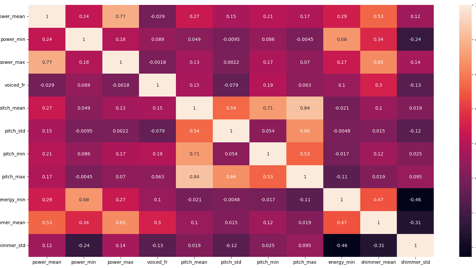
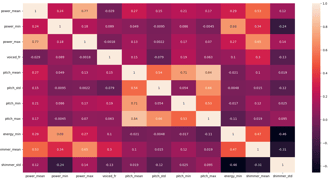
Highly correlated features (above 0.85) were removed.
PCA was applied to MFCC data, reducing dimensionality while retaining 95% of the variance.
RFECV was used to select the most relevant features.
Model Training and Evaluation
Five classification models were evaluated and their hyperparameters tuned using GridSearchCV with 5-fold cross-validation:
Logistic Regression
SVM
Random Forest
Gradient Boosting
KNN
All five models were conbined into an ensemble soft-voting model meaning that the final prediction is based on the weighted average of the probabilities predicted by each base model.
Model performance was evaluated using accuracy, as the data was balanced with no weighted cost associated with misclassification.
Further research should focus on:
Refined Feature Engineering:
Exploring additional features capturing nuanced aspects of speech (prosody, linguistic cues, sentiment).
Experimenting with different feature aggregation techniques beyond basic statistical measures.
Using a sliding window approach for more fine-grained predictions.
Data Augmentation:
Employing techniques like adding noise or time stretching to increase training data diversity.
Advanced Modelling Techniques:
Considering deep learning models like CNNs or RNNs to capture complex relationships in audio data.
Image showing predictor correlations after highly correlated variables removed
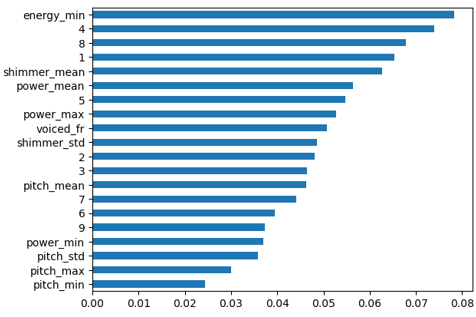
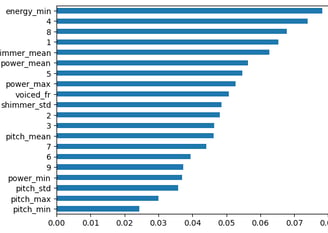
Image showing the feature importance as determined by a Random-forest-classifier
Image showing the cross validation accuracy during recursive-feature-elimination-with-cross-validation
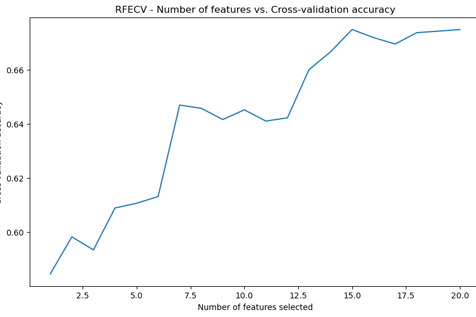
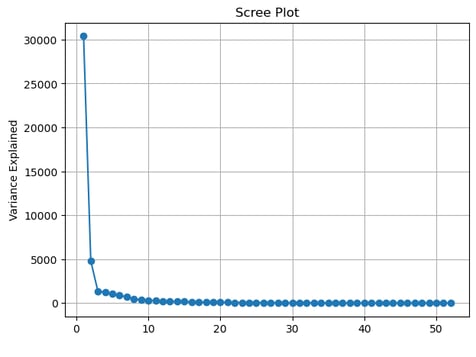
Image showing the scree plot from the PCA analysis performed on the MFCC derived predictors.